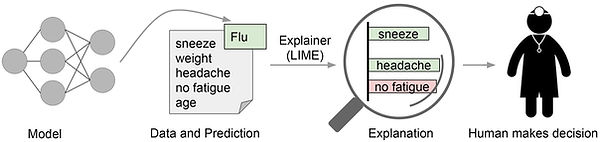
Local Interpretable Model-Agnostic Explanations (LIME)
LIME is a model-agnostic technique that explains the predictions of any black-box machine learning model, including neural networks, decision trees, and support vector machines. It works by approximating the black-box model locally with a simpler, interpretable model such as a linear model, and then using this simpler model to generate explanations for individual predictions.
The basic idea behind LIME is to perturb the input data by adding or removing features, and then observe the effect on the output of the black-box model. By repeating this process many times, LIME builds a local approximation of the black-box model that can be used to explain how the model arrived at a particular prediction.
Source: Local Interpretable Model-Agnostic Explanations (LIME): An Introduction
Here's a high-level overview of how it works:
-
Select the instance to be explained: Choose an instance for which you want to generate an explanation. This could be an image, text, or any other type of input that the black-box model is designed to handle.
-
Generate local perturbations: LIME generates a set of perturbations of the selected instance by randomly adding or removing features (e.g., words in a text document, pixels in an image, etc.) and creating new instances.
-
Obtain the predictions of the black-box model: Each perturbed instance is passed through the black-box model, and the corresponding prediction is obtained.
-
Fit an interpretable model: LIME fits a simpler, interpretable model (such as a linear regression model) to the perturbed instances and their corresponding predictions. The interpretable model is designed to approximate the behavior of the black-box model locally.
-
Generate local feature importance: The interpretable model is used to generate feature importance scores for each feature in the original instance. These scores indicate how much each feature contributes to the prediction of the black-box model for the selected instance.
-
Present the explanation: The feature importance scores are used to generate an explanation for the prediction of the black-box model for the selected instance. This can be done in various ways, such as highlighting important words in a text document or showing the most relevant regions of an image.
By repeating this process for different instances, LIME can generate a set of local explanations that can help users understand how the black-box model is making its predictions. This can be particularly useful in cases where the black-box model is complex or difficult to interpret, such as deep neural networks.
Sample Code (Python)
In this example, we first define a text classification model using scikit-learn's make_pipeline function. We then train the model on some sample data and fit it to a TfidfVectorizer and a MultinomialNB classifier.
Next, we define a LIME explainer using the LimeTextExplainer class. We then define an instance to be explained and generate an explanation using the explain_instance method of the explainer object. Finally, we print the explanation as a list of (feature, weight) tuples.
This code generates an explanation for a single instance, but you can use the same process to generate explanations for multiple instances in a loop. Note that you may need to adjust the parameters of the LimeTextExplainer class and the explain_instance method to suit your specific use case.